

C/C++培训
达内IT学院
400-996-5531

400-996-5531
jvm字节码对应于数组操作时有一套特定的指令,当字节码要在虚拟机上生成一个含有10个元素的整形数组时,它会执行以下指令:
sipush 10
newarray int
astore 0
第一条语句sipush 10 先将数组所包含的元素的个数压到堆栈上,生成数组时对应一条特定指令就是 newarray, 该指令后面跟着要生成的数组类型,如果想生成整形数组,那么newarray 指令后面就跟着int, 如果想生成浮点型数组,那么newarray 后面就得跟着float. 执行完这两条语句后堆栈顶部存储着含有10个元素的整形数组的对象实例:
stack: int[10]
接着的指令astore 0把堆栈上的含有10个元素的整形数组对象转移到局部变量队列:
stack: null
local_list: int[10]
字节码要想读取数组中的某个元素的值时,例如要读取a[7]的值时,可以执行如下指令:
aload 0
sipush 7
iaload
aload 0指令把存储在局部变量队列的数组对象加载到堆栈,然后把要读取的数组元素的下标压入堆栈,由于我们要读取的数组元素的下标是7,因此我们通过指令sipush 7把数值7压入堆栈,最后指令iaload把a[7]的值压入到堆栈,由于我们刚生成的数组a[10]还没有初始化,所以a[7]的值是0,上面的指令执行后,虚拟机的情况如下:
stack: 0, int[10]
local_stack: int[10]
指令iload前面的i与数组的类型要一致,如果数组类型是浮点型,对应的指令就应该是fload.
如果要想对数组中的某个元素赋值,加入我们要把10赋值给数组下标为3的元素,也就是我们想实现a[3] = 10,那么我们可以执行如下指令:
aload 0
sipush 3
sipush 10
iastore
指令aload 0先把数组对象加载到堆栈,然后把要赋值的元素的下标压入堆栈,由于我们想对下标为3的元素赋值,所以通过指令sipush 3把数值3压到堆栈。接着把要赋值的内容压入堆栈,因为我们想给a[3]赋值10,所以通过sipush 10 把数值10 压入堆栈,最后执行指令iastore 把数值10存入数值下标为3的元素,iastore前面的i与数组的类型是相关的,如果数组类型是浮点值,那么对应的指令应该是fastore。
有了上面的理论基础后,我们看看如何把下面的C语言代码编译成java字节码:
void main() {
int a[10];
a[3] = 10;
printf("value of a[3] is :%d", a[3]);
}
代码首先定义了一个含有10个元素的整形数组,当编译成java字节码时,我们的编译器首先需要使用相应指令在虚拟机中生成对应的数组对象,相应代码如下,在ProgramGenerator.java中:
public void createArray(Symbol symbol) {
if (arrayNameMap.containsKey(symbol.getScope())) {
if (arrayNameMap.get(symbol.getScope()).equals(symbol.getName())) {
return;
}
}
arrayNameMap.put(symbol.getScope(), symbol.getName());
Declarator declarator = symbol.getDeclarator(Declarator.ARRAY);
if (declarator == null) {
return;
}
String type = "";
if (symbol.hasType(Specifier.INT)) {
type = "int";
}
int num = declarator.getElementNum();
this.emit(Instruction.SIPUSH, ""+num);
this.emit(Instruction.NEWARRAY , type);
int idx = getLocalVariableIndex(symbol);
this.emit(Instruction.ASTORE, "" + idx);
}
symbol对应的就是变量a的Symbol对象,arrayNameMap的定义如下:
private Map<String, String> arrayNameMap = new HashMap<String, String>();
哈希表的key对应的是变量的作用域,哈希表的值对应变量名,由于上面代码中,变量a的作用域是”main”, 它的变量名是”a”,因此代码会在哈希表中加入一条记录(“main”,”a”)。代码执行是首先判断该变量对应的数组是否已经生成过,如果生成过,那就直接返回,如果没有生成过,那么先判断输入的变量是否属于数组类型,如果是,那就获取数组的类型,接着通过delcarator.getElementNum()获得数组的元素个数,通过getLocalVariableIndex()获得变量在队列中的位置,然后根据前面讲解过的数值生成指令,把相关指令输出到java汇编代码文件中。
我们再看看读取数组元素的实现:
public void readArrayElement(Symbol symbol, int index) {
Declarator declarator = symbol.getDeclarator(Declarator.ARRAY);
if (declarator == null) {
return;
}
int idx = getLocalVariableIndex(symbol);
this.emit(Instruction.ALOAD, ""+idx);
this.emit(Instruction.SIPUSH, ""+index);
this.emit(Instruction.IALOAD);
}
根据前面的理论,我们先通过aload指令把数组对象从队列加载到堆栈上,接着把要读取的元素下标压入队列,最后通过iaload指令把元素的值从数组中加载到堆栈上。
接着是修改元素值的实现:
public void writeArrayElement(Symbol symbol, int index, Object value) {
Declarator declarator = symbol.getDeclarator(Declarator.ARRAY);
if (declarator == null) {
return;
}
int idx = getLocalVariableIndex(symbol);
if (symbol.hasType(Specifier.INT)) {
int val = (int)value;
this.emit(Instruction.ALOAD, ""+idx);
this.emit(Instruction.SIPUSH, ""+index);
this.emit(Instruction.SIPUSH, ""+val);
this.emit(Instruction.IASTORE);
}
}
数组元素写入的实现跟我们前面的理论描述是一致的,先是通过指令aload把数组对象加载到堆栈,然后把要写入的元素下标压入堆栈,最后把要写入元素的值压入堆栈,接着执行iastore指令,把相关信息写入数组的相应元素。
当编译器对代码进行解析时,遇到数组的读写,例如解析到语句a[3] = 10;时,在UnaryNodeExecutor.java中的以下代码会被调用:
case CGrammarInitializer.Unary_LB_Expr_RB_TO_Unary:
child = root.getChildren().get(0);
symbol = (Symbol)child.getAttribute(ICodeKey.SYMBOL);
child = root.getChildren().get(1);
int index = (Integer)child.getAttribute(ICodeKey.VALUE);
try {
Declarator declarator = symbol.getDeclarator(Declarator.ARRAY);
if (declarator != null) {
Object val = declarator.getElement(index);
root.setAttribute(ICodeKey.VALUE, val);
ArrayValueSetter setter = new ArrayValueSetter(symbol, index);
root.setAttribute(ICodeKey.SYMBOL, setter);
root.setAttribute(ICodeKey.TEXT, symbol.getName());
//create array object on jvm
ProgramGenerator.getInstance().createArray(symbol);
ProgramGenerator.getInstance().readArrayElement(symbol, index);
}
数组元素的读写对应的语法表达式是:
UNARY -> UNARY LB EXPR RB
执行该表达式的正是上面给定的代码,在读写数组元素时,我们先调用createArray在jvm的堆栈上生成数组对象,再调用readArrayElement来读取数组中给定元素的值。
编译器中负责修改数组元素的部分是ArrayValueSetter类,所以我们也在里面进行相应指令的输出,代码如下:
public void setValue(Object obj) {
Declarator declarator = symbol.getDeclarator(Declarator.ARRAY);
try {
declarator.addElement(index, obj);
ProgramGenerator.getInstance().writeArrayElement(symbol, index, obj);
System.out.println("Set Value of " + obj.toString() + " to Array of name " + symbol.getName() + " with index of " + index);
} catch (Exception e) {
// TODO Auto-generated catch block
System.err.println(e.getMessage());
e.printStackTrace();
System.exit(1);
}
}
编译器在解读数组元素的修改语句时,顺便调用writeArrayElement生成jvm上对数组元素进行修改的指令。
上面代码完成后运行,编译器把给定的C语言代码编译成如下的java汇编语言代码:
.class public CSourceToJava
.super java/lang/Object
.method public static main([Ljava/lang/String;)V
sipush 3
sipush 10
newarray int
astore 0
aload 0
sipush 3
iaload
sipush 10
aload 0
sipush 3
sipush 10
iastore
sipush 3
aload 0
sipush 3
iaload
istore 1
getstatic java/lang/System/out Ljava/io/PrintStream;
ldc "value of a[3] is :"
invokevirtual java/io/PrintStream/print(Ljava/lang/String;)V
getstatic java/lang/System/out Ljava/io/PrintStream;
iload 1
invokevirtual java/io/PrintStream/print(I)V
getstatic java/lang/System/out Ljava/io/PrintStream;
ldc "
"
invokevirtual java/io/PrintStream/print(Ljava/lang/String;)V
return
.end method
.end class
把上面java汇编代码编译成二进制字节码,运行在虚拟机上的结果如下:
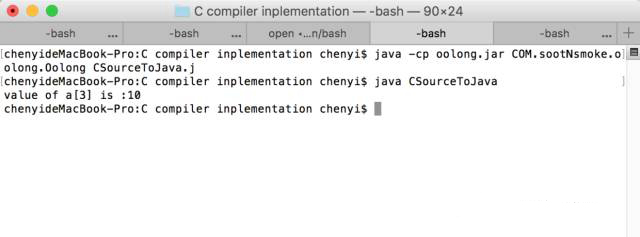
通过运行结果可见,我们编译器的实现是正确的。
还需要提一下的是,我们的编译器在编译的时候,产生了冗余语句,因为编译器在解析源码时,一旦遇到数字字符串,它就会生成一条把对应数字进行压栈的语句,在上面java汇编代码中,第一条语句:
sipush 3
其实就是冗余语句,它是完全没有必要的,出现这条语句的原因是,当我们的编译器在解析语句a[3] = 10;的时候,读取到字符3的时候,它不管三七二十一,立马产生一条将常量压入堆栈的语句,也就是上面那条语句。解读数值常量的代码也是在UnaryNodeExecutor.java中,代码如下:
case CGrammarInitializer.Number_TO_Unary:
....
ProgramGenerator.getInstance().emit(Instruction.SIPUSH, "" + value);
break;
正是上面的代码导致编译器一旦解读到数值常量就立马输出一条sipush指令,虽然冗余语句不会对编译结果造成影响,但是它会让我们生成的最终代码在运行上的速度下降。
正因为这个原因,在解读语句a[3]=10;时,读取到最后的数值10时,编译器又会生成一条冗余指令,也就是第12行的sipush 10.由于冗余语句的存在,会使得最终生成的java汇编代码与预想的多了一些指令,大家把结果编译出来后,读取最终Java汇编代码时,注意不要被迷惑,后面我们会想办法处理冗余指令这个问题。



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



