

C/C++培训
达内IT学院
400-996-5531

400-996-5531
C++ 是一门面向对象编程语言,但是这个对象到底长什么样子,为什么会是这个样子,你真的了解吗?这个问题,其实正是对象模型(Object Model)所关心的,本文从对象内存布局的角度出发,来窥探一下对象模型,具体想深入学习的话,推荐大家读一下 Lippman 的《Inside The C++ Object Model》[1](侯捷的中译本更好一些,修正了原文中的不少勘误)。
首先,我们来看一个具体的问题。对于一个没有非静态数据成员的类,如果取sizeof,结果会是怎样?如果拍脑袋说是0肯定是不行的,因为如果要 new 一个对象,必须要说明开多大内存。有些经验的程序员应该知道,通常编译器给一个空类分配的大小是1个字节,用来占位。不过,这个结论也只是假设这是一个非常简单的类,如果引入虚函数,引入类继承等概念,结果就不确定了。对于下面这段代码,如果你很确定类 D1 ~ D6 的大小及布局,本文后面的内容就不用继续读了,因为后面我们主要也是围绕这些东西在聊。
Listing 1 - empty classes
1 class Empty {}; 2 class D1 : public Empty {}; 3 class D2 : public Empty { 4 public: 5 virtual void Test1() {} 6 virtual void Test2() {} 7 }; 8 class D3 : virtual public Empty {}; 9 class D4 : virtual public Empty {};10 class D5 : public D3, public D4 {};11 class D6 : public D1, public D4 {};
对于上文定义的这些空类的大小,大家可以自己动手尝试一下,不同编译环境下,结果也可能不一样。空类的问题我们先放一边,如果定义一个类,到底哪些方面会影响到这个类的对象的内存布局呢?以下几处是我们的重点怀疑对象,我们会分为上下两篇来进行具体的讨论。
增加数据成员?
改变 public/private access 修饰符会有影响吗?
增加普通的成员方法呢?
增加继承层次会增加类的大小吗?
引入多态呢?
多重继承呢?
虚拟继承呢?
下面,我们逐一来看看,如果引入这些变化,会对一个对象的内存布局都有哪些影响。
1. C struct类型
C struct 类型在 C++ 中也是类,只是每个成员都是 POD 类型[2],所有数据成员public 访问,没有复杂数据成员,也没有定义方法。这种类的大小取决于数据成员的类型大小总和和内存对齐引入的 padding 大小,这个也是为了和 C 语言兼容。对于下面这段示例代码,简单说明一下,Line 3~5中直接在类定义中对数据成员初始化是 C++11 引入的特性;HexDump 是一个小函数,传入一个对象的地址,打印对象在内存中的实际内容;本文中所有示例代码编译执行环境是 64 位 ubuntu 14.04 ,编辑器为 g++。
Listing 2 - C struct
1 class A { 2 public: 3 int a = 0x12345678; 4 char b = 'b'; 5 float c = 12.5; 6 }; 7 8 int main() { 9 A t;1011 printf("sizeof(t) = %ld\n", sizeof(t));12 printf("&t = %p\n", &t);13 printf("&t.a = %p\n", &t.a);14 printf("&t.b = %p\n", &t.b);15 printf("&t.c = %p\n", &t.c);16 HexDump(&t);1718 return 0;19 }// output as below:// sizeof(t) = 12// &t = 0x7ffeb3c3f3d0// &t.a = 0x7ffeb3c3f3d0// &t.b = 0x7ffeb3c3f3d4// &t.c = 0x7ffeb3c3f3d8// 0x7ffeb3c3f3d0: 0x78 0x56 0x34 0x12 0x62 0x00 0x00 0x00 // 0x7ffeb3c3f3d8: 0x00 0x00 0x48 0x41
从输出结果,我们可以看到类A的大小为12
sizeof(A) = sizeof(int) + sizeof(char) + padding + sizeof(float)
从内存布局可以看到,数据存放顺序和类中定义的次序一致。从 b 和 c 对应的地址,可以看出有3个字节的 padding,具体内存对齐规则可以参考相关资料[3]。这里顺便提一下静态数据成员,引入静态成员并不会影响到一个类的大小,因为它并不和具体的对象绑定,相比全局静态数据而言,简单地说只是多了一层访问控制。
2. 引入访问控制修饰符
如果有些数据成员变成私有成员,会对内存大小和布局有影响吗?我们可以看一下下面的示例代码,将 A 中的 c 改成私有的。
Listing 3 - add access specifiers
1 class A { 2 public: 3 int a = 0x12345678; 4 char b = 'b'; 5 private: 6 float c = 12.5; 7 }; 8 9 int main() {10 A t;1112 printf("sizeof(t) = %ld\n", sizeof(t));13 printf("&t = %p\n", &t);14 printf("&t.a = %p\n", &t.a);15 printf("&t.b = %p\n", &t.b);16 printf("%f\n", *((float*)((char*)&t + sizeof(t) - 4)));17 HexDump(&t);1819 return 0;20 }// output as below:// sizeof(t) = 12// &t = 0x7ffdfd38f460// &t.a = 0x7ffdfd38f460// &t.b = 0x7ffdfd38f464// 12.500000// 0x7ffdfd38f460: 0x78 0x56 0x34 0x12 0x62 0x00 0x00 0x00 // 0x7ffdfd38f468: 0x00 0x00 0x48 0x41
从输出结果,我们可以看到,类的大小和内存布局没有任何变化,所以改变数据成员的访问修饰并不会对内存布局有任何影响,Line16 专门打印了 c 的值。
3. 增加普通成员方法
如果增加一些方法,会影响到类的大小吗?我们可以看一下下面的示例代码,
Listing 4 - add methods
1 class A { 2 public: 3 A(int i, char j, float k) : a(i), b(j), c(k) {} 4 5 int GetA() { return a; } 6 char GetB() { return b; } 7 float GetC() const { return c; } 8 9 private:10 int a;11 char b;12 float c;13 };1415 int g_a = 100;16 int GetA() { return g_a; }1718 int main() {19 A t(0x12345678, 'b', 12.5);20 printf("sizeof(t) = %ld\n", sizeof(t));21 HexDump(&t);22 t.GetA();23 GetA();24 return 0;25 }// output as below:// sizeof(t) = 12// 0x7fffa6f5e2c0: 0x78 0x56 0x34 0x12 0x62 0x00 0x00 0x00 // 0x7fffa6f5e2c8: 0x00 0x00 0x48 0x41
从输出结果,我们可以看到,引入方法定义,并不会改变内存布局。细心的读者可能发现,我们多定义了一个全局函数 GetA() 。这里主要是想多聊几句类的成员方法。这些成员方法和普通的全局函数有什么不一样呢?我们主要从函数名和用法两个方面来看。
从函数名或者函数原型来看,C++ 为了支持函数重载,所以对编译出的函数名符号进行了 name mangling [4],通过 nm/objdump 结合 c++fillt ,我们可以还原函数名,具体如下。可以看出来,类名也是函数名的一部分,所以可以区别于全局同名函数。
Listing 5 - nm
$ nm a.out000000000040057d T _Z4GetAv000000000040061e W _ZN1A4GetAEv00000000004005e8 W _ZN1AC1Eicf
Listing 6 - name mangling
$ nm a.out | c++filt -n000000000040057d T GetA()000000000040061e W A::GetA()00000000004005e8 W A::A(int, char, float)
除了函数名之外,具体使用上来看,类方法需要通过对象来调用,具体到汇编层面,可以看到类的方法接收的第一个参数是对象的地址( this 指针):
Listing 7 - method member call
leaq -16(%rbp), %rax => 对应栈地址&tmovq %rax, %rdi => %rdi为函数第一个参数[5]call _ZN1A4GetAEv => t.GetA()call _Z4GetAv => GetA()
4. 单继承
如果从 A 派生出一个新的类 B ,同时定义了 B 自己的数据成员,那么 sizeof(B) 应该多大呢?
Listing 8 - single inheritance
1 class A { 2 public: 3 A(int i = 1, char j = 'a', float k = 0) : a(i), b(j), c(k) {} 4 5 int GetA() { return a; } 6 char GetB() { return b; } 7 float GetC() const { return c; } 8 9 private:10 int a;11 char b;12 float c;13 };14 15 class B : public A {16 public:17 18 private:19 int ba = 0x1122;20 char bb = 'b';21 float bc = 99.9;22 };23 24 int main() {25 A t1(0x12345678, 'b', 12.5);26 B t2;27 28 printf("sizeof(t1) = %ld\n", sizeof(t1));29 HexDump(&t1);30 printf("sizeof(t2) = %ld\n", sizeof(t2));31 HexDump(&t2);32 }// output as below:// sizeof(t1) = 12// 0x7fffd6edc710: 0x78 0x56 0x34 0x12 0x62 0x00 0x00 0x00 // 0x7fffd6edc718: 0x00 0x00 0x48 0x41 // sizeof(t2) = 24// 0x7fffd6edc720: 0x01 0x00 0x00 0x00 0x61 0x00 0x00 0x00 // 0x7fffd6edc728: 0x00 0x00 0x00 0x00 0x22 0x11 0x00 0x00 // 0x7fffd6edc730: 0x62 0x07 0x40 0x00 0xcd 0xcc 0xc7 0x42
和预期的一样,sizeof(B) = sizeof(A) + sizeof(new data members),对象 t1 占用 12 字节,对象 t2 占用 24 字节。从 t2 的内存布局看,起始 12 字节存放的是基类数据,随后存放新增数据,这个次序不能反,如果你随意存放的话,当执行类似语句 A* p = &t2; 的时候是不是还要做额外的偏移计算?换句话说,这种顺序存放也是为什么一个派生类的对象可以直接拿来做基类对象使用而没有额外开销的原因。
Figure 1 - single inheritance

5. 多态
谈到面向对象,避不开多态的概念。所谓多态,就是可以通过基类指针或者引用,实现访问派生类(实际对象类型)定义的方法,这也是很多设计模式赖以存在的基础。但是正是因为这一灵活性,增加了对象模型的复杂度,上面提到的那些基本内存布局已经无法满足功能需求了,因为只有数据部分,没有类型信息。
怎么办?
目前主流的编译器都是通过引入虚表的方法来实现多态特性,具体来说,如果一个类中定义了虚函数,那么编译器就会给这个类生成一个虚函数列表( vtable,里面主要存放对应的虚函数地址列表,如果没有重写虚函数,就存放基类的虚函数地址),同时,在构造具体对象的时候(运行时),除去数据成员所占用的内存外,增加一个虚表指针 vptr 指向对应类的虚表中首个虚函数地址。这样一来,编译器就知道,如果访问的是普通成员函数,就直接 call 对应的函数地址,如果访问的是虚函数,就通过 vptr 索引到具体的虚表,根据函数名映射到具体的虚函数地址存放位置,然后获取实际的函数地址。下面,我们通过示例代码来看一下,
Listing 9 - polymorphism
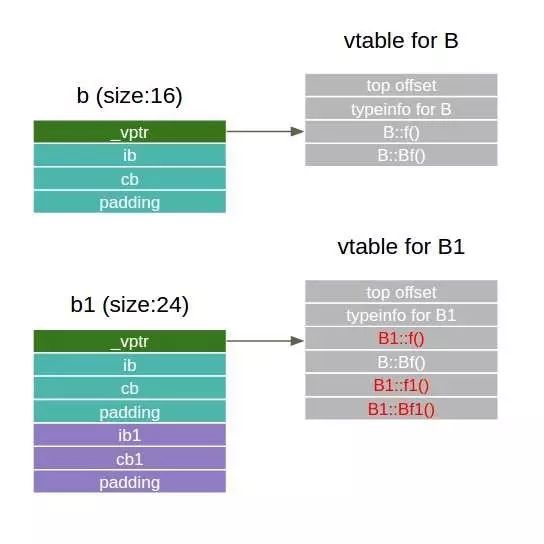
1 class B { 2 public: 3 B() : ib(0), cb('B') {} 4 void nb() {} 5 virtual void f() { printf("B::f()\n"); } 6 virtual void Bf() { printf("B::Bf()\n"); } 7 8 private: 9 int ib;10 char cb;11 };12 13 class B1 : public B {14 public:15 B1() : ib1(11), cb1('1') {}16 virtual void f() { printf("B1::f()\n"); }17 virtual void f1() { printf("B1::f1()\n"); }18 virtual void Bf1() { printf("B1::Bf1()\n"); }19 20 private:21 int ib1;22 char cb1;23 };24 25 int main() {26 B b;27 B1 b1;28 29 B& rb = b1;30 rb.f();31 b1.f();32 33 printf("sizeof(b) = %ld\n", sizeof(b));34 HexDump(&b);35 printf("sizeof(b1) = %ld\n", sizeof(b1));36 HexDump(&b1);37 38 return 0;39 }// output as below:// B1::f()// B1::f()// sizeof(b) = 16// 0x7ffdffc64930: 0x30 0x0b 0x40 0x00 0x00 0x00 0x00 0x00 // 0x7ffdffc64938: 0x00 0x00 0x00 0x00 0x42 0x00 0x00 0x00 //// sizeof(b1) = 24// 0x7ffdffc64940: 0xf0 0x0a 0x40 0x00 0x00 0x00 0x00 0x00 // 0x7ffdffc64948: 0x00 0x00 0x00 0x00 0x42 0x00 0x00 0x00 // 0x7ffdffc64950: 0x0b 0x00 0x00 0x00 0x31 0x7f 0x00 0x00
从输出结果看,基类大小超过了数据成员和对齐内存的大小。进一步,从具体内存布局看,前面8字节内容和数据成员无关,后续8字节中,前一半对应的ib(0),0x42 对应的 cb(‘B’) ,最后是3字节 padding。那前面这个8字节到底是什么呢?其实它是一个地址 0x400b30,通过 c++filt 查看,它对应的并不是 B 的 vtable起始地址,而是 vtable for B + 16,这个地址对应内存中存放的内容可以通过 gdb 查看,它正好是 B::f() 的地址。对于 b1 而言,情况类似,只是除去16 字节的数据成员外,前 8 字节对应的也是一个地址 0x400af0,它指的是 vtable for B1 + 16,里面存放的正好对应 B1::f() 的地址。
通过 rb 来访问 f() 的时候,因为 rb 只是一个对象引用(指向内存地址 &b1 ),编译器无法确定这个对象的真实类型,又因为 f() 在类 B 中是一个虚函数,所以通过 vptr 找到 B1 的 vtable , 然后通过查表来得到具体的函数地址 B1::f() 。说的有点啰嗦,大家可以结合下面的汇编代码来看就清楚些,顺便配图示意。
Figure 2 - polymorphism
Listing 10 - virtual function call
// 下面对应rb.f()leaq -32(%rbp), %raxmovq %rax, -56(%rbp)movq -56(%rbp), %raxmovq (%rax), %raxmovq (%rax), %raxmovq -56(%rbp), %rdxmovq %rdx, %rdicall *%rax
Listing 11 - non-virtual function call
// 下面对应b1.f()leaq -32(%rbp), %raxmovq %rax, %rdicall _ZN2B11fEv
前面讨论的这些都是通过指针或引用的方式来说的,如果是具体对象来访问成员函数的话就用不着那么复杂,因为这个时候已经确定了对象的类型,直接 call 就好,这也是为什么在平时的编码中,如无必要,就不要引入虚函数,不要把事情复杂化(虚函数调用和对象构造都增加了额外的负担)。
查看虚表内容,也可以直接用 gdb 的命令 info vtbl ,对于上面的例子,我们可以看到 b 和 b1 中指向的虚表内容。特别留意一下 rb ,为什么看到的和 b1 的不同?其实道理很简单,因为它毕竟是一个基类的引用,从语法编译的角度,它没有能力知道派生类中新增虚函数的信息。
Listing 13 - gdb info vtbl
(gdb) info vtbl bvtable for 'B' @ 0x400b30 (subobject @ 0x7fffffffdc00):[0]: 0x400804 <B::f()>[1]: 0x40081c <B::Bf()>(gdb) info vtbl b1vtable for 'B1' @ 0x400af0 (subobject @ 0x7fffffffdc10):[0]: 0x40086c <B1::f()>[1]: 0x40081c <B::Bf()>[2]: 0x400884 <B1::f1()>[3]: 0x40089c <B1::Bf1()>(gdb) info vtbl rbvtable for 'B' @ 0x400af0 (subobject @ 0x7fffffffdc10):[0]: 0x40086c <B1::f()>[1]: 0x40081c <B::Bf()>
除此之外,你也可以通过编译选项查看类的结构信息,比如 g++ 的 -fdump-class-hierarchy 来生成描述文件,里面也有比较详细类的布局描述。
好了,能坚持看到这里的,先给自己点个赞。这次我们就先聊到这里,多继承和虚拟继承的问题,相对而言要复杂得多,我们在下篇中继续讨论,大家可以关注「技艺丛谈」公众号,阅读下次分享。最后留几个小问题,感兴趣的可以思考一下。
对象的 vptr 是在什么时候完成初始化的?
在类的构造函数或者析构函数中,调用虚函数安全吗?为什么?
可以在成员函数中执行 delete this 吗?为什么?
6. 参考资料
[1]Inside The C++ Object Model. By Stanley B.Lippman.
[2]#/w/cpp/concept/PODType
[3]#/wiki/Data_structure_alignment
[4]#/wiki/Name_mangling
[5]#/161938/assembly-register-calling-convention-tutorial
我们继续聊C++对象模型,重点从多继承和虚拟继承的引入来看,为了支持这些特性,编译器需要多做多少工作。这里再次说明一下,本文和上篇《C++ 对象模型探秘——上篇》做的讨论都是和编译器具体实现相关的,不同平台不同编译器上具体实现方法并不相同,而且同一编译器的实现也不是一层不变。
多继承
通过上篇我们知道,引入多态特性会让类的布局增加一个vptr,派生类对象和基类对象的首部都会有一个vptr,只是指向不同的虚表。如果在此基础上,引入多继承会是什么样子呢?我们还是通过一个具体的例子来看看。
Listing 1 - multiple inheritance
1 class B { 2 public: 3 B() : ib(0), cb('B') {} 4 void nb() {} 5 virtual void f() { printf("B::f()\n"); } 6 virtual void Bf() { printf("B::Bf()\n"); } 7 8 private: 9 int ib;10 char cb;11 };12 13 class B1 : public B {14 public:15 B1() : ib1(11), cb1('1') {}16 virtual void f() { printf("B1::f()\n"); }17 virtual void f1() { printf("B1::f1()\n"); }18 virtual void Bf1() { printf("B1::Bf1()\n"); }19 20 private:21 int ib1;22 char cb1;23 };24 25 class B2 : public B {26 public:27 B2() : ib2(12), cb2('2') {}28 virtual void f() { printf("B2::f()\n"); }29 virtual void f2() { printf("B2::f2()\n"); }30 virtual void Bf2() { printf("B2::Bf2()\n"); }31 32 private:33 int ib2;34 char cb2;35 };36 37 class D : public B1, public B2 {38 public:39 D() : id(100), cd('D') {}40 virtual void f() { printf("D::f()\n"); }41 virtual void f1() { printf("D::f1()\n"); }42 virtual void f2() { printf("D::f2()\n"); }43 virtual void Df() { printf("D::Df()\n"); }44 45 private:46 int id;47 char cd;48 };49 50 int main() {51 B b;52 B1 b1;53 B2 b2;54 D d;55 56 printf("sizeof(b) = %ld\n", sizeof(b));57 HexDump(&b);58 printf("sizeof(b1) = %ld\n", sizeof(b1));59 HexDump(&b1);60 printf("sizeof(b2) = %ld\n", sizeof(b2));61 HexDump(&b2);62 printf("sizeof(d) = %ld\n", sizeof(d));63 HexDump(&d);64 65 return 0;66 }
上面的例子中,我们定义了一个基类B,随后自它派生了两个类B1, B2,最后基于B1和B2又派生出D。当然,多继承除了在两千年左右曾流行一时的模板编程中用的比较多,通常好多公司都是不建议使用多继承的,更不必说这种有着号称“菱形继承”问题的结构。这里,我们主要是为了分析编译器对这种结构是如何处理的,帮助大家加深理解,也让大家明白为啥不建议使用多继承。
Figure 1 - 菱形继承

上面程序的输出结果如下,
Listing 2 - multiple inheritance output
// output as below:
// sizeof(b) = 16
// 0x7ffc86555250: 0x70 0x0d 0x40 0x00 0x00 0x00 0x00 0x00
// 0x7ffc86555258: 0x00 0x00 0x00 0x00 0x42 0x00 0x00 0x00
//
// sizeof(b1) = 24
// 0x7ffc86555260: 0x90 0x0d 0x40 0x00 0x00 0x00 0x00 0x00
// 0x7ffc86555268: 0x00 0x00 0x00 0x00 0x42 0x00 0x00 0x00
// 0x7ffc86555270: 0x0b 0x00 0x00 0x00 0x31 0x7f 0x00 0x00
//
// sizeof(b2) = 24
// 0x7ffc86555280: 0xd0 0x0d 0x40 0x00 0x00 0x00 0x00 0x00
// 0x7ffc86555288: 0x00 0x00 0x00 0x00 0x42 0x00 0x00 0x00
// 0x7ffc86555290: 0x0c 0x00 0x00 0x00 0x32 0x00 0x00 0x00
//
// sizeof(d) = 56
// 0x7ffc865552a0: 0x10 0x0e 0x40 0x00 0x00 0x00 0x00 0x00
// 0x7ffc865552a8: 0x00 0x00 0x00 0x00 0x42 0x7f 0x00 0x00
// 0x7ffc865552b0: 0x0b 0x00 0x00 0x00 0x31 0x00 0x00 0x00
// 0x7ffc865552b8: 0x50 0x0e 0x40 0x00 0x00 0x00 0x00 0x00
// 0x7ffc865552c0: 0x00 0x00 0x00 0x00 0x42 0x00 0x00 0x00
// 0x7ffc865552c8: 0x0c 0x00 0x00 0x00 0x32 0x00 0x00 0x00
// 0x7ffc865552d0: 0x64 0x00 0x00 0x00 0x44 0x00 0x00 0x00
从结果中看,问题比较明显,在对象d中,最顶层的基类B的数据部分(ib,cb)存在两份,从而导致了二义性,即在D的成员方法中访问ib/cb的时候存在歧义,不知道具体访问哪一个内存位置。让人不爽的是,编译器对这种继承关系没有任何告警,只是在你访问ib/cb的时候才有编译告警。在上面例子中,我们没有访问ib/cb的代码,所以程序顺利编译而且运行也没有问题,对象d被成功创建。具体解剖一下d,我们可以看到,多继承可能会引入多个vptr。不过,除去vptr之外,结构很简单,分成三个部分,分别对应类B1, B2和D,我们下面用子对象B1, B2,D来描述。
Figure 2 - inside object d
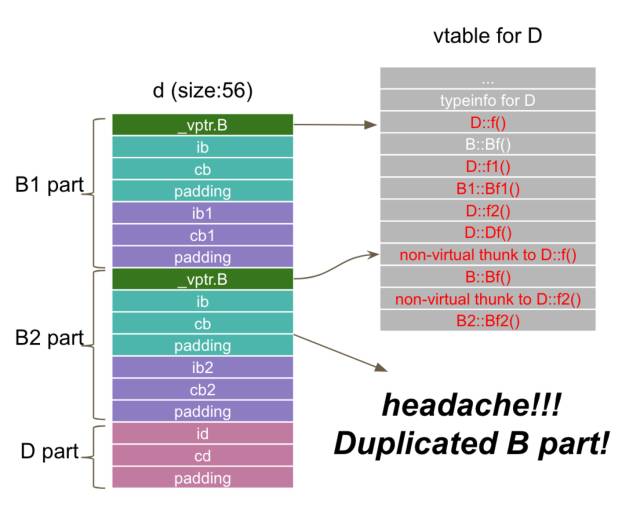
对象d的具体构造过程也和之前的单继承没有太多区别,分别构造子对象B1, B2,然后是D,当然构造B1, B2的时候又都先构造B子对象,最后D的构造函数负责更新vptr。也正是由于这种构造逻辑导致了无法避免地存在了子对象B的两个副本(B1, B2子对象中各一个)。我们通过格式化的汇编来看一下具体d的构造过程(下面略去了非关键代码)。
Listing 3 - multiple inheritance D construction
D::D(): ... movq -8(%rbp), %rax =>B1子对象起始地址 movq %rax, %rdi call B1::B1() =>调用B1构造函数,完成B1子对象初始化 movq -8(%rbp), %rax addq $24, %rax movq %rax, %rdi =>B2子对象起始地址 call B2::B2() =>调用B2构造函数,完成B2子对象初始化 movq -8(%rbp), %rax movq vtable for D+16, (%rax) =>更新vptr movq -8(%rbp), %rax movq vtable for D+80, 24(%rax) =>更新vptr movq -8(%rbp), %rax movl $100, 48(%rax) =>初始化id movq -8(%rbp), %rax movb $68, 52(%rax) =>初始化cdB1::B1(): ... movq -8(%rbp), %rax =>B子对象起始地址 movq %rax, %rdi call B::B() =>调用B构造函数,完成B子对象初始化 movq -8(%rbp), %rax movq vtable for B1+16, (%rax) =>更新vptr movq -8(%rbp), %rax movl $11, 16(%rax) =>初始化ib1 movq -8(%rbp), %rax movb $49, 20(%rax) =>初始化cb1B2::B2(): ... movq -8(%rbp), %rax =>B子对象起始地址 movq %rax, %rdi call B::B() =>调用B构造函数,完成B子对象初始化 movq -8(%rbp), %rax movq vtable for B2+16, (%rax) =>更新vptr movq -8(%rbp), %rax movl $12, 16(%rax) =>初始化ib2 movq -8(%rbp), %rax movb $50, 20(%rax) =>初始化cb2B::B(): ... movq -8(%rbp), %rax movq vtable for B+16, (%rax) =>更新vptr movq -8(%rbp), %rax movl $0, 8(%rax) =>初始化ib movq -8(%rbp), %rax movb $66, 12(%rax) =>初始化cb
分析了上面对象d的构造过程,我们能想到,如果要确保子对象B只有占一份内存空间,那么我们就不能让B1, B2的构造函数去负责子对象B的构造(初始化),只能引入新的解决办法,C++提供的解决办法是引入虚拟继承。在谈虚拟继承前,我们看到多继承不仅增加了类构造的复杂度,而且容易引入了二义性的问题,所以一般我们不建议使用多继承。
虚拟继承
为了解决上面遇到的二义性的问题,C++引入了虚拟继承,这一下让对象模型复杂度提高了很多,原本一个虚表已经无法很好的解决问题,还需要引入其他机制。具体需要解决的问题其实很直接,到底谁来负责子对象B的构造?交给B1, B2看来是不合适的,只能交给D自己了(其实是给继承层次中最深的那个类)。这样一来就导致了B1, B2构造函数的复杂化,因为在构造d对象的时候,调用B1的构造函数是不能初始化子对象B的;但是在构造一个单独的B1对象,比如上例中的b1的时候,B1的构造函数又需要对子对象B的初始化负责。g++和clang++使用的办法是引入一个VTT(virtual table table)来解决这个难题。具体从用户代码层面来看,只用修改上例中的Line 13, 25,增加virtual关键字即可。
Listing 4 - virtual inheritance
...13 class B1 : virtual public B {...25 class B2 : virtual public B {...
程序的输出结果如下,
Listing 5 - virtual inheritance output
sizeof(b) = 16
0x7ffcf5fcbb10: 0xb0 0x0d 0x40 0x00 0x00 0x00 0x00 0x00
0x7ffcf5fcbb18: 0x00 0x00 0x00 0x00 0x42 0x00 0x00 0x00
sizeof(b1) = 32
0x7ffcf5fcbb20: 0xd8 0x0d 0x40 0x00 0x00 0x00 0x00 0x00
0x7ffcf5fcbb28: 0x0b 0x00 0x00 0x00 0x31 0x00 0x00 0x00
0x7ffcf5fcbb30: 0x10 0x0e 0x40 0x00 0x00 0x00 0x00 0x00
0x7ffcf5fcbb38: 0x00 0x00 0x00 0x00 0x42 0x00 0x00 0x00
sizeof(b2) = 32
0x7ffcf5fcbb40: 0x38 0x0e 0x40 0x00 0x00 0x00 0x00 0x00
0x7ffcf5fcbb48: 0x0c 0x00 0x00 0x00 0x32 0x00 0x00 0x00
0x7ffcf5fcbb50: 0x70 0x0e 0x40 0x00 0x00 0x00 0x00 0x00
0x7ffcf5fcbb58: 0x00 0x00 0x00 0x00 0x42 0x00 0x00 0x00
sizeof(d) = 56
0x7ffcf5fcbb60: 0x98 0x0e 0x40 0x00 0x00 0x00 0x00 0x00
0x7ffcf5fcbb68: 0x0b 0x00 0x00 0x00 0x31 0x7f 0x00 0x00
0x7ffcf5fcbb70: 0xd8 0x0e 0x40 0x00 0x00 0x00 0x00 0x00
0x7ffcf5fcbb78: 0x0c 0x00 0x00 0x00 0x32 0x00 0x00 0x00
0x7ffcf5fcbb80: 0x64 0x00 0x00 0x00 0x44 0x00 0x00 0x00
0x7ffcf5fcbb88: 0x10 0x0f 0x40 0x00 0x00 0x00 0x00 0x00
0x7ffcf5fcbb90: 0x00 0x00 0x00 0x00 0x42 0x00 0x00 0x00
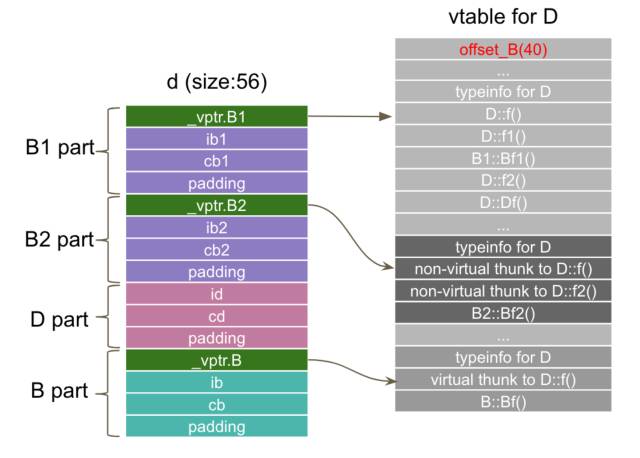
从结果来看,有两个明显的变化。第一,b1和b2的布局发生改变,而且都变大了;第二,d中子对象B现在只有一个副本了,但是d占用的内存空间却没有减少。我们还是从汇编代码来看一下,d的构造有什么变化。从下面的构造函数代码来看,首先是对子对象B的构造,直接调用B的构造函数完成初始化;其次,调用B1的构造函数,但是传递了两个参数,一个是我们知道的对象起始地址(this指针),另一个是新的参数VTT for D+8,我们暂时先放一下;接着就是调用B2的构造函数,和B1类似,也是传了两个参数;最后是更新所有的vptrs和D引入的数据成员id, cd。
Listing 6 - virtual inheritance D construction
D::D(): ... subq $16, %rsp movq %rdi, -8(%rbp) movq -8(%rbp), %rax addq $40, %rax =>子对象B的offset movq %rax, %rdi call B::B() =>调用构造函数,初始化子对象B movl VTT for D+8, %edx movq -8(%rbp), %rax movq %rdx, %rsi movq %rax, %rdi call _ZN2B1C2Ev =>调用B1构造函数,版本C2 movl VTT for D+24, %eax movq -8(%rbp), %rdx addq $16, %rdx movq %rax, %rsi movq %rdx, %rdi call _ZN2B2C2Ev =>调用B1构造函数,版本C2 movl vtable for D+24, %edx movq -8(%rbp), %rax movq %rdx, (%rax) =>更新_vptr.B1 movl $40, %edx movq -8(%rbp), %rax addq %rax, %rdx movl vtable for D+144, %eax movq %rax, (%rdx) =>更新_vptr.B movl vtable for D+88, %edx movq -8(%rbp), %rax movq %rdx, 16(%rax) =>更新_vptr.B2 movq -8(%rbp), %rax movl $100, 32(%rax) =>更新id movq -8(%rbp), %rax movb $68, 36(%rax) =>更新cd ...
通过下面的汇编代码,我们可以看到,编译器给B1和B2都生成了两个版本的构造函数,其中一个版本(我们就称它为C1版本)需要负责子对象B的构造,另一个(C2版本)不需要。而在D的构造函数中,看到调用的B1, B2的构造函数都是不用考虑子对象B的构造的那个版本(C2版本),因为对B的构造直接由D的构造函数来完成。
Listing 7 - multi-version constructors
_ZN2B1C1Ev: =>B1::B1(),版本是C1 ... subq $16, %rsp movq %rdi, -8(%rbp) movq -8(%rbp), %rax addq $16, %rax movq %rax, %rdi call B::B() =>C1版本需要调用B的构造函数对子对象B初始化 movl vtable for B1+24, %edx movq -8(%rbp), %rax movq %rdx, (%rax) movl $16, %edx movq -8(%rbp), %rax addq %rax, %rdx movl vtable for B1+80, %eax movq %rax, (%rdx) movq -8(%rbp), %rax movl $11, 8(%rax) =>初始化ib1 movq -8(%rbp), %rax movb $49, 12(%rax) =>初始化cb1 ..._ZN2B1C2Ev: =>B1::B1(),版本是C2,不需要初始化子对象B,函数开始的一堆操作主要是从传入第二参数中(临时虚表)获取抽象基类信息,并更新vptr。 ... movq %rdi, -8(%rbp) movq %rsi, -16(%rbp) movq -16(%rbp), %rax movq (%rax), %rdx movq -8(%rbp), %rax movq %rdx, (%rax) movq -8(%rbp), %rax movq (%rax), %rax subq $24, %rax movq (%rax), %rax movq %rax, %rdx movq -8(%rbp), %rax addq %rax, %rdx movq -16(%rbp), %rax movq 8(%rax), %rax movq %rax, (%rdx) movq -8(%rbp), %rax movl $11, 8(%rax) =>初始化ib1 movq -8(%rbp), %rax movb $49, 12(%rax) =>初始化cb1 ..._ZN2B2C1Ev: =>B2::B2(),版本是C1 ... subq $16, %rsp movq %rdi, -8(%rbp) movq -8(%rbp), %rax addq $16, %rax movq %rax, %rdi call B::B() =>C1版本需要调用B的构造函数对子对象B初始化 movl $_ZTV2B2+24, %edx movq -8(%rbp), %rax movq %rdx, (%rax) movl $16, %edx movq -8(%rbp), %rax addq %rax, %rdx movl $_ZTV2B2+80, %eax movq %rax, (%rdx) movq -8(%rbp), %rax movl $12, 8(%rax) =>初始化ib2 movq -8(%rbp), %rax movb $50, 12(%rax) =>初始化cb2 ... _ZN2B2C2Ev: =>B2::B2(),版本是C2 ... movq %rdi, -8(%rbp) movq %rsi, -16(%rbp) movq -16(%rbp), %rax movq (%rax), %rdx movq -8(%rbp), %rax movq %rdx, (%rax) movq -8(%rbp), %rax movq (%rax), %rax subq $24, %rax movq (%rax), %rax movq %rax, %rdx movq -8(%rbp), %rax addq %rax, %rdx movq -16(%rbp), %rax movq 8(%rax), %rax movq %rax, (%rdx) movq -8(%rbp), %rax movl $12, 8(%rax) =>初始化ib2 movq -8(%rbp), %rax movb $50, 12(%rax) =>初始化cb2 ...B::B(): ... movq %rdi, -8(%rbp) movq -8(%rbp), %rax movq vtable for B+16, (%rax) movq -8(%rbp), %rax movl $0, 8(%rax) => 初始化ib movq -8(%rbp), %rax movb $66, 12(%rax) => 初始化cb …
对于C1版本的构造函数,不是什么新概念,之前都有讨论过,我们就不用细说了。对于新引入的C2版本,到底有什么不一样呢?除了不需要负责虚基类的构造之外,这个构造函数还需要多接收一个参数,它和VTT有关。
那到底VTT是什么东西,做什么用的呢?其实也比较容易理解,VT就是virtual table,虚表,用来存放每个类中实现的虚函数地址列表,在构造对象的时候通过vptr来指向具体的虚表,从而可以支持多态特性。
VTT就是virtual table table,管理虚表的表。为什么需要管理?因为每个类的虚表不再唯一了。通过nm查看符号表,我们可以看到多了下面两个vtable,这两个表的引入确保了d的构造过程中,每个阶段的构造结果在语义上的正确性。这句话理解起来可能有点费劲,我们拆分一下来看,就是对象d的构造可以分为几步,分别对应子对象B,B1,B2和D。在构造B1子对象的时候,C1版本的构造函数已经不能使用了,因为它初始化vptr指向的是vtable B1的内容,而vtable B1里面存放的抽象基类对象的位置信息和vtable D中的是不同的,所以没法用,但是在C2版本的构造函数里又不能直接用vtable D的信息,编译器就只有构造一个临时的虚表,里面含有抽象基类的位置信息和一些B1能看到的虚函数信息,并给这个临时表起了一个名字,类似construction vtable for B1-in-D,意思是它只是给构造D对象的过程中构造B1子对象的时候用。具体怎么用呢,就是我们上面提到的通过参数传给B1的C2版本构造函数。对于B2子对象也是类似,也有一个临时虚表。这些临时的表都是给D服务的,所以D需要有个地方来索引这些临时虚表,VTT for D就诞生了。
Listing 8 - vtables in virtual inheritance
0000000000400fe0 V construction vtable for B1-in-D0000000000401040 V construction vtable for B2-in-D
最后,我们得到的对象d的内存布局如下图所示。
Figure 3 - inside object d in virtual inheritance
结束语
写了这么多,也许有人会说,我为什么需要知道内存模型这些东西呢,不知道不也coding很多年吗,感觉这些没什么用啊。确实,花时间去学习这些东西并不像告诉你一个容器用法的效果来的那么立竿见影,特别是在现在这个快餐文化、拿来主义的年代,花时间在这上面感觉有点浪费。不过,作为一名程序员,多去了解一下我们平时常用的工具,多去熟悉一下支撑代码运行的背后逻辑,做到知其然知其所以然总不会是坏事。虽然很多代码并不是我们自己创造的,但也不能只做代码的搬运工吧。



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



