

C/C++培训
达内IT学院
400-996-5531

400-996-5531
在实践中怎么去写好一手代码,这个还真的得多看看人家的代码;个人觉得,我们可以多参照Linux的编程风格。
下面是个人在工作中的一些总结,不一定很规范或合乎逻辑,仅供参考:
1)首要的一点就是代码的工整性,也就是排版,个人觉得要做到:不要让人家看起来,觉得你的代码凌乱,而是要有规可寻,看起来整洁。代码的缩进对齐方式用空格符,这样就不会产生不同环境打开代码文档缩进乱序的情况。
2)变量跟函数的命名规则,这个是一定要注意的,命名的规则,一方面是要能很好的体现出这个变量或函数的大概意思,让人一目了然;另一方面就是要遵循某一命名准则,比如说,我一般的做法是,glRawDataRxFinish 前面的 gl 代表 global,然后后面的意思是原始数据接收完成,且每个单词首字母应大写。
3)宏定义和枚举型变量,宏定义跟枚举型变量一定要所有字母都大写,并且在单词之间用下划线隔开,如:

4)所有变量之间的操作符号都留一个空格,这样看起来比较清爽,比如:
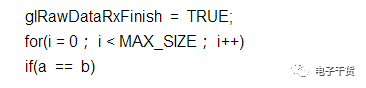
5)代码中尽量,或者一定不要出现magic number,这会让人看不懂的,比如说: if(a == 100),此时我们就不明白了,这个a是什么意思呢。这时就应该用有意义的宏定义来定义100,如下示:
#define MAX_RX_BUFFER_SIZE 100
6)合理使用编译开关,我们很多时候会写一些测试代码来验证自己的代码,但测完之后很可能就直接删除或者注释掉;这里有个更好的办法,就是使用宏定义编译开关,比如说我们可以这样来写测试代码:

7)尽量做到编译连warning都没有,有就继续检查改进。
8)尽量少用全局变量,虽然说全局变量的操作效率更高,但不利于代码的阅读、复用、移植,当全局变量越来越多时,在不同函数之间窜来窜去,修改或判断时代码逻辑会变得很复杂,时间久了自己维护起来都可能会骂一句。
9)可以的话,注释尽量使用英文,因为用中文注释,代码可能换个编译器,注释就乱码了。
10)相关性比较紧密或者是模块化里面的多个变量,尽量把他们放在一个结构体里面。
11)设计到纯算法的模块,比如说 fft / fir / iir 等,尽量直接打包封装成library的方式,提供接口给人使用即可。
12)个人或者多人之间的代码管理,个人推荐用 git 跟 Gerrit(code review)相结合的方式,这样可以很好的做好软件版本控制和代码管理,自己所有的修改操作都可以一目了然,同时等于把你的代码备份到了另外一个主机上。



Copyright © Tedu.cn All Rights Reserved 京ICP备08000853号-56  京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有
京公网安备 11010802029508号 达内时代科技集团有限公司 版权所有



